Using itsdm to a real species: Africa savanna elephant
Lei Song
2022-11-16
Source:vignettes/itsdm_example.Rmd
itsdm_example.RmdSet up
Install your missing packages
install.packages("rnaturalearth")
install.packages("rgbif")
install.packages("lubridate")
options(repos = c(
ropensci = 'https://ropensci.r-universe.dev',
CRAN = 'https://cloud.r-project.org'))
install.packages('scrubr')Prepare environmental variables
The objective of this vignette is to provide an example of how to use
categorical variables in itsdm and show a reasonable
workflow of SDM, not to create an optimal model.
Before building a formal good model, we should try something as a start. Here we use the variables listed below to create a primary model.
- Bioclimatic variables
- Protected area and land cover type as categorical variables.
Note that maps of the protected area and land cover types are
prepared and provided in this package. You could use
system.file with file names to find them like the
following.
library(stars)
library(rnaturalearth, quietly = T)
# Bioclimatic variables
data("mainland_africa")
bios <- worldclim2(var = 'bio',
bry = mainland_africa,
path = tempdir(),
nm_mark = 'africa') %>% st_normalize()
# Protected area
fname <- 'extdata/wdpa_africa_10min.tif'
wdpa <- system.file(fname, package = 'itsdm') %>%
read_stars() %>% setNames('wdpa')
# Land cover
fname <- 'extdata/landcover_africa_10min.tif'
landcover <- system.file(fname, package = 'itsdm') %>%
read_stars() %>% setNames('landcover')
# Merge them together as variable stack
variables <- c(bios,
c(wdpa, landcover) %>% merge(name = "band"),
along = 3) %>% split("band")
variables <- variables %>%
mutate(wdpa = factor(wdpa),
landcover = factor(landcover))
rm(fname, bios, wdpa, landcover)Prepare occurrence from GBIF
The official name for the African savanna elephant is Loxodonta africana (Blumenbach, 1797), which could be used to search in GBIF. According to the following reasons:
- It is not reasonable to use the very past data.
- The distribution of elephants is relatively stable over a short time.
We choose the most recent occurrence observations (2010 to now) with an assumption that landcover changes could be ignorable between 2010 and now.
library(lubridate, quietly = T)
library(rgbif, quietly = T)
## Set the time interval for querying on GBIF
start_year <- 2010
year <- sprintf('%s,%s', start_year, year(Sys.Date()))
# Search
nm_search <- "Loxodonta africana (Blumenbach, 1797)"
occ <- occ_search(scientificName = nm_search,
hasCoordinate = TRUE,
limit = 200000,
year = year,
hasGeospatialIssue = FALSE)Even though the occurrence dataset obtained from GBIF has high quality and its API provides available options to do some screening. There are still some disturbances contained in occurrence. As a complement, we do extra steps to clean the occurrence data. The steps include:
- Basic Geo-cleaning. For example, clean the records with impossible
or incomplete coordinates. Or clean the duplicated records. We did this
step using package
scrubr. - Range-cleaning. Strict the records to a specific area, which is an extra step for Geo-cleaning.
- Spatial deduction. This step is to remove duplicates at the spatial resolution of raster.
-
Environmental cleaning. Detect and/or drop the
records with outlier environmental values. We could do this step before
dimension reduction of the environmental variable because
outlier.treecompares records with the general condition.
library(scrubr, quietly = T)
# Step1: Basic Geo-cleaning on occurrence
occ_clean <- occ$data %>%
select(name, decimalLongitude,
decimalLatitude, eventDate, key) %>%
setNames(c('name', 'longitude',
'latitude', 'date', 'key')) %>%
mutate(date = as.Date(date)) %>%
dframe() %>%
coord_impossible() %>%
coord_incomplete() %>%
coord_unlikely()
# Step2: Range-cleaning on occurrence
## For example, Africa savanna elephant only could appear in Africa
data("mainland_africa")
occ_clean_sf <- occ_clean %>%
st_as_sf(coords = c('longitude', 'latitude'),
crs = 4326)
occ_clean_sf <- st_intersection(mainland_africa, occ_clean_sf)
# Step3: Spatial deduction
occ_clean_sf <- st_rasterize(
occ_clean_sf,
template = variables %>% select('bio1') %>%
mutate(bio1 = NA)) %>%
st_xy2sfc(as_points = T) %>% st_as_sf() %>%
select(geometry)
# Step4: Environmental-cleaning on occurrence
## We used a very high z_outliers
## It is tricky to remove environmental outliers
## because it is hard to tell if they are outliers or
## just rare records.
occ_outliers <- suspicious_env_outliers(
occ_clean_sf,
variables = variables,
z_outlier = 16,
outliers_print = 4L,
visualize = FALSE)
#> Reporting top 4 outliers [out of 26 found]
#>
#> row [128] - suspicious column: [bio14] - suspicious value: [1.00]
#> distribution: 98.734% <= 0.00 - [mean: 0.00] - [sd: 0.00] - [norm. obs: 78]
#> given:
#> [bio11] > [25.71] (value: 26.22)
#>
#>
#> row [288] - suspicious column: [bio14] - suspicious value: [2.00]
#> distribution: 97.701% <= 0.00 - [mean: 0.00] - [sd: 0.00] - [norm. obs: 340]
#> given:
#> [bio17] <= [8.00] (value: 8.00)
#> [bio18] <= [162.00] (value: 156.00)
#>
#>
#> row [1] - suspicious column: [bio17] - suspicious value: [1.00]
#> distribution: 92.857% <= 0.00 - [mean: 0.00] - [sd: 0.00] - [norm. obs: 26]
#> given:
#> [bio14] <= [1.00] (value: 0.00)
#> [bio5] > [39.79] (value: 41.24)
#>
#>
#> row [36] - suspicious column: [bio17] - suspicious value: [1.00]
#> distribution: 92.857% <= 0.00 - [mean: 0.00] - [sd: 0.00] - [norm. obs: 26]
#> given:
#> [bio14] <= [1.00] (value: 0.00)
#> [bio5] > [39.79] (value: 40.49)
plot(occ_outliers)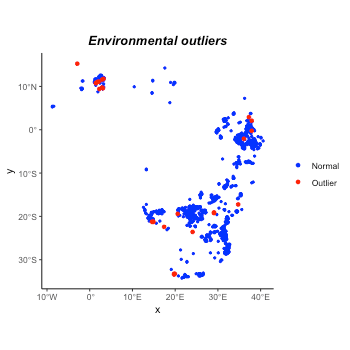
According to the figure and the prior knowledge of the Africa savanna
elephant, we decide not to drop the outliers. The outliers seem more
like rare records. In addition, if they are real outliers, the later
isolation.forest could detect them again. Now let’s
organize the occurrence before the next step.
occ <- occ_outliers$pts_occ
rm(occ_clean_sf)Understand the correlations between variables
Function dim_reduce in this package allows the user to
reduce the dimensions arbitrarily for numeric environmental variables
based on their correlation. Thus, here we do such thing to numeric ones
of variables and keep the categorical ones.
# Split continuous and categorical variables
# and reduce dimensions for continuous ones
cat_vars <- c('wdpa', 'landcover')
var_cat <- variables %>% select(all_of(cat_vars))
var_con <- variables %>% select(-all_of(cat_vars))
var_con_rdc <- dim_reduce(var_con, threshold = 0.75, samples = occ)
var_con_rdc
#> Dimension reduction
#> Correlation threshold: 0.75
#> Original variables: bio1, bio2, bio3, bio4, bio5, bio6, bio7, bio8, bio9,
#> bio10, bio11, bio12, bio13, bio14, bio15, bio16, bio17, bio18, bio19
#> Variables after dimension reduction: bio1, bio2, bio3, bio6, bio12, bio14,
#> bio18, bio19
#> ================================================================================
#> Reduced correlations:
#> bio1 bio2 bio3 bio6 bio12 bio14 bio18 bio19
#> bio1 1.00 0.03 -0.22 0.64 0.04 -0.40 -0.41 0.27
#> bio2 0.03 1.00 -0.44 -0.66 -0.56 -0.47 -0.34 -0.30
#> bio3 -0.22 -0.44 1.00 0.43 0.34 0.44 0.22 0.23
#> bio6 0.64 -0.66 0.43 1.00 0.45 0.11 -0.10 0.48
#> bio12 0.04 -0.56 0.34 0.45 1.00 0.59 0.49 0.54
#> bio14 -0.40 -0.47 0.44 0.11 0.59 1.00 0.43 0.30
#> bio18 -0.41 -0.34 0.22 -0.10 0.49 0.43 1.00 -0.07
#> bio19 0.27 -0.30 0.23 0.48 0.54 0.30 -0.07 1.00
# Put together
var_con <- var_con_rdc$img_reduced
variables <- do.call(c, list(split(var_con, 'band'), var_cat))
rm(cat_vars, var_cat, var_con, var_con_rdc)It is highly not recommended to merge attributes of
variables to band or any other dimension if
there are any categorical layers in it unless you know pretty well about
what you are doing. Because merging will force categorical values to
change to numeric ones, you know that it is tricky to convert between
factors and numbers in R.
# If you really want to merge
## At least could ensure the values are the original values
var_merge <- variables
var_merge <- var_merge %>%
mutate(wdpa = as.integer(levels(wdpa))[wdpa],
landcover = as.integer(levels(landcover))[landcover])
var_merge <- merge(var_merge, name = 'band')
rm(var_merge)By far, the variables is the environmental variable
stack with numeric ones with low correlation and categorical ones.
Split occurrence to training and test
# Make occurrences
occ <- occ %>% mutate(id = 1:nrow(.))
set.seed(11)
occ_sf <- occ %>% sample_frac(0.7)
occ_test_sf <- occ %>% filter(! id %in% occ_sf$id)
occ_sf <- occ_sf %>% select(-id) %>%
mutate(observation = 1)
occ_test_sf <- occ_test_sf %>% select(-id) %>%
mutate(observation = 1)
rm(occ)Now both occurrence and environmental variables are ready to use for modeling.
Build a isolation_forest species distribution
model
At this step, the users could use strategies like grid search and preferred evaluation metrics to find the optimal arguments for the model. As an example, here we use a set of arguments:
ntrees = 200sample_rate = 0.9-
ndim = 4because we includes 2 categorical variables categ_cols = c('wdpa', 'landcover')
# Do modeling
it_sdm <- isotree_po(obs = occ_sf,
obs_ind_eval = occ_test_sf,
variables = variables,
categ_vars = c('wdpa', 'landcover'),
ntrees = 200L,
sample_size = 0.9,
ndim = 4,
seed = 10L)Visualize results
Predicted environmental suitability
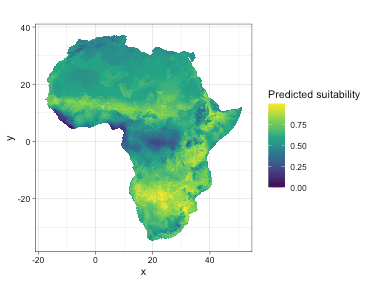
This indicates African savanna elephants have a very large potential habitat on this continent. Like more explicit field research indicates that the potential range of African elephants could be more than five times larger than its current extent (https://scitechdaily.com/african-elephants-have-plenty-of-habitat-if-spared-from-the-ivory-trade/). As a mega-mammal, elephants could adapt themselves to survive harsh environments.
Presence-only model evaluation
# According to training dataset
# it_sdm$eval_train
# plot(it_sdm$eval_train)
# According to test dataset
it_sdm$eval_test
#> ===================================
#> Presence-only evaluation:
#> CVI with 0.25 threshold: 0.006
#> CVI with 0.5 threshold: 0.144
#> CVI with 0.75 threshold: 0.590
#> CBI: 0.393
#> AUC (ratio) 0.880
#> ===================================
#> Presence-background evaluation:
#> Sensitivity: 0.818
#> Specificity: 0.774
#> TSS: 0.591
#> AUC: 0.870
#> Similarity indices:
#> Jaccard's similarity index: 0.667
#> Sørensen's similarity index: 0.800
#> Overprediction rate: 0.217
#> Underprediction rate: 0.182
plot(it_sdm$eval_test)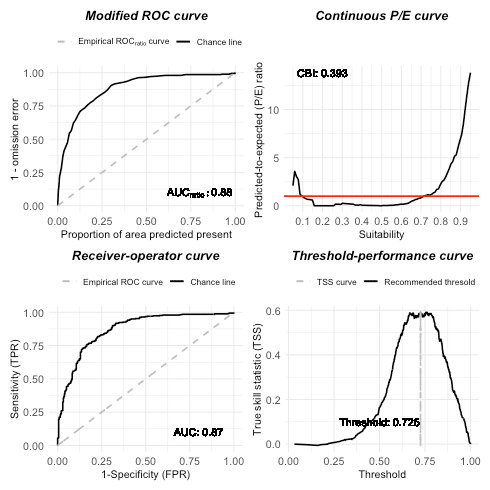
According to the evaluation, the model has the potential to improve, for instance, by adding more explanatory features: forest cover, distance to water, elevation, slope, human influence, etc. According to the continuous Boyce index and TSS curve, the model overestimates some “completely” unsuitable areas, for example, Sahara (see above suitability map). One assumption is that several occurrence data locate in the Namib desert. And land cover map reflects this information to Sahara. But Namib desert is very narrow and close to natural resources, which makes it suitable for elephants. However, deep Sahara is not the same story. So, including a feature describing the distance to water could be helpful to improve the model.
Response curves
Response curves of environmental variables show how the suitability of a variable to this species changes when its value is varied.
Marginal response curves
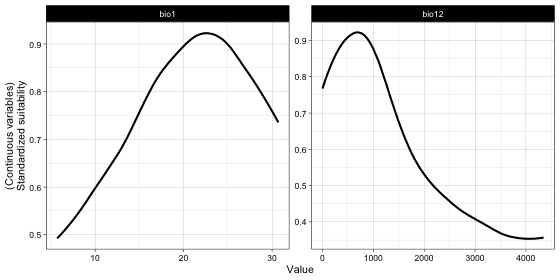
We checked the marginal response curves of two bioclimatic variables. The response curve of bio1 and bio12 are very reasonable and indicate the preferred temperature and precipitation conditions.
Independent response curves
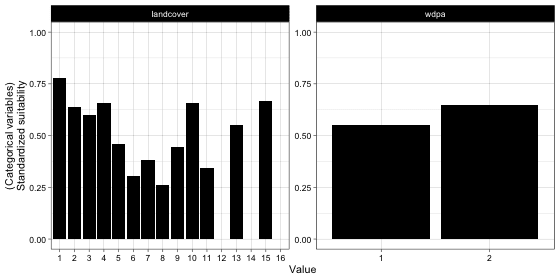
According to the figure above, elephants go beyond protected areas often. This matches with the previous study related to elephant movement. Thus, the binary protected area is not a good modeling variable. Distance to the protected area might be, however. Because usually, there are plenty of natural resources (food, water, etc.) within the protected area. Elephants might like to stay around these protected areas. The response of land cover indicates that elephants strongly prefer to stay in some landscape, such as forest, shrub, wetland, cropland, and built-up. Here is some useful information:
- Forest/shrub cover ratio may be another helpful feature regarding land cover.
- Distance to human residential (e.g., village) may be helpful.
Shapley value based dependence curves
## Variable dependence scatter points with fitted curves made by SHAP test
plot(it_sdm$shap_dependences, smooth_line = FALSE)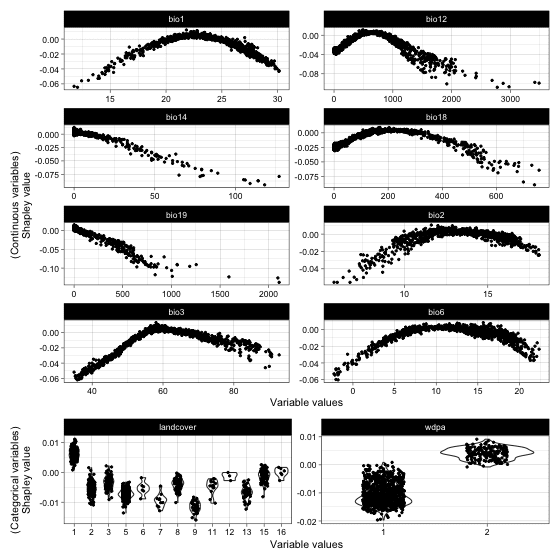
Now, let’s overview all variable responses made by Shapley values. All variables seem to be the environmental features of elephants. Precipitation seems like a solid decisive factor. We could analyze feature importance further to diagnose the contribution of each variable.
Variable importance
Variable importance analysis is another way to understand the relationship between environmental variables and species distribution. It also could help to improve model performance.
it_sdm$variable_analysis
#> Relative variable importance
#> ===================================
#> Methods: Jackknife test and SHAP
#> Numer of variables: 10
#> ===================================
#> Jackknife test
#> Based on Pearson correlation (Max value is 1)
#> [Training dataset]:
#> bio12 With only: ////////////////////////////////// 0.757
#> Without : //////////////////////////////////////////// 0.972
#> bio18 With only: //////////////////////////// 0.631
#> Without : //////////////////////////////////////////// 0.978
#> landcover With only: //////////////////////////// 0.62
#> Without : //////////////////////////////////////////// 0.986
#> bio3 With only: /////////////////////////// 0.605
#> Without : //////////////////////////////////////////// 0.975
#> bio19 With only: //////////////////////// 0.523
#> Without : /////////////////////////////////////////// 0.96
#> bio6 With only: /////////////////////// 0.52
#> Without : //////////////////////////////////////////// 0.982
#> wdpa With only: ///////////////////// 0.461
#> Without : //////////////////////////////////////////// 0.985
#> bio1 With only: //////////////////// 0.447
#> Without : //////////////////////////////////////////// 0.977
#> bio14 With only: ///////////////// 0.368
#> Without : //////////////////////////////////////////// 0.98
#> bio2 With only: /////////////// 0.341
#> Without : //////////////////////////////////////////// 0.982
#> [Test dataset]:
#> bio12 With only: //////////////////////////////////// 0.799
#> Without : //////////////////////////////////////////// 0.97
#> bio3 With only: /////////////////////////// 0.59
#> Without : //////////////////////////////////////////// 0.975
#> landcover With only: ////////////////////////// 0.586
#> Without : //////////////////////////////////////////// 0.987
#> bio18 With only: ////////////////////////// 0.578
#> Without : //////////////////////////////////////////// 0.98
#> bio19 With only: ///////////////////////// 0.56
#> Without : /////////////////////////////////////////// 0.954
#> bio6 With only: ///////////////////// 0.462
#> Without : //////////////////////////////////////////// 0.984
#> wdpa With only: //////////////////// 0.452
#> Without : //////////////////////////////////////////// 0.985
#> bio1 With only: ////////////////// 0.411
#> Without : //////////////////////////////////////////// 0.976
#> bio14 With only: //////////////// 0.345
#> Without : //////////////////////////////////////////// 0.983
#> bio2 With only: //////////// 0.27
#> Without : //////////////////////////////////////////// 0.984
#> ======================================================================
#> Jackknife test
#> Based on AUC ratio (Max value of traing and test are 0.870 and 0.880)
#> [Training dataset]:
#> bio12 With only: ////////////////////////////////////// 0.842
#> Without : ////////////////////////////////////// 0.839
#> bio18 With only: //////////////////////////////////// 0.792
#> Without : /////////////////////////////////////// 0.87
#> bio3 With only: ////////////////////////////////// 0.76
#> Without : /////////////////////////////////////// 0.875
#> bio6 With only: //////////////////////////////// 0.719
#> Without : /////////////////////////////////////// 0.871
#> bio1 With only: /////////////////////////////// 0.696
#> Without : /////////////////////////////////////// 0.862
#> landcover With only: /////////////////////////////// 0.681
#> Without : /////////////////////////////////////// 0.876
#> wdpa With only: ////////////////////////////// 0.673
#> Without : /////////////////////////////////////// 0.86
#> bio2 With only: ///////////////////////////// 0.65
#> Without : /////////////////////////////////////// 0.869
#> bio19 With only: //////////////////////// 0.535
#> Without : /////////////////////////////////////// 0.873
#> bio14 With only: ////////////// 0.308
#> Without : //////////////////////////////////////// 0.881
#> [Test dataset]:
#> bio12 With only: ///////////////////////////////////// 0.833
#> Without : ////////////////////////////////////// 0.849
#> bio18 With only: /////////////////////////////////// 0.777
#> Without : //////////////////////////////////////// 0.878
#> bio3 With only: ///////////////////////////////// 0.744
#> Without : //////////////////////////////////////// 0.887
#> landcover With only: /////////////////////////////// 0.691
#> Without : //////////////////////////////////////// 0.885
#> wdpa With only: ////////////////////////////// 0.677
#> Without : /////////////////////////////////////// 0.87
#> bio1 With only: ////////////////////////////// 0.672
#> Without : /////////////////////////////////////// 0.875
#> bio6 With only: ////////////////////////////// 0.67
#> Without : //////////////////////////////////////// 0.878
#> bio2 With only: //////////////////////////// 0.612
#> Without : /////////////////////////////////////// 0.876
#> bio19 With only: /////////////////////// 0.51
#> Without : //////////////////////////////////////// 0.888
#> bio14 With only: ////////////// 0.311
#> Without : //////////////////////////////////////// 0.888
#> ======================================================================
#> SHAP (mean(|Shapley value|))
#> [Training dataset]:
#> bio12 : ########################################### 0.015
#> bio19 : ################################## 0.012
#> bio3 : ############################### 0.011
#> bio18 : ############################ 0.01
#> bio1 : ######################### 0.009
#> wdpa : ##################### 0.008
#> bio14 : #################### 0.007
#> bio6 : ################## 0.007
#> bio2 : ################# 0.006
#> landcover : ################# 0.006
#> [Test dataset]:
#> bio12 : ############################################# 0.016
#> bio19 : ####################################### 0.014
#> bio3 : ############################## 0.011
#> bio18 : ########################## 0.009
#> bio1 : ######################## 0.008
#> wdpa : ##################### 0.008
#> bio14 : ################### 0.007
#> bio6 : ################# 0.006
#> landcover : ################# 0.006
#> bio2 : ############### 0.005From the text above, annual precipitation is the most important decisive factor. Because precipitation decides the supply of food and water. Temperature is not a very critical constraint to elephants. It indicates that compared to food/water, elephants could tolerate the extreme temperature. Bio14 (Precipitation of Driest Month) is a not-important variable agreed by the Jackknife test and SHAP test. One assumption is that all animals must deal with limited precipitation over the driest month, common in the African savanna. In the Jackknife test, landcover has a relatively high contribution when working alone. But the model performs very well without it. The same to wdpa. In the Shapley value-based test, these two variables are judged as less important. It indicates that landcover and wdpa strongly correlate with some other variables. Changing the way to use them might be necessary to improve the model performance.
Shapley value summary plot is another way to interpret variable contribution.
var_contrib <- variable_contrib(
it_sdm$model,
it_sdm$vars_train,
it_sdm$vars_train)
# Plot general contribution for all observations
plot(var_contrib)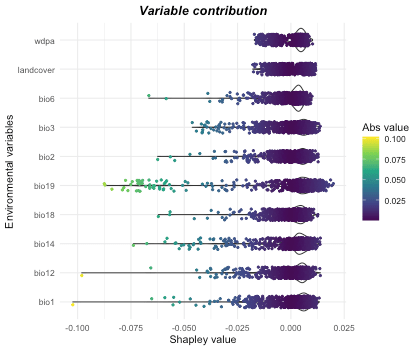
Presence-absence map
Use function convert_to_pa to convert suitability to
probability of occurrence.
# Convert to presence-absence map
pa_map <- convert_to_pa(it_sdm$prediction,
method = "logistic",
beta = 0.2,
species_prevalence = 0.2,
threshold = 0.5,
visualize = FALSE)
ggplot() +
geom_stars(data = pa_map$probability_of_occurrence) +
scale_fill_viridis_c('Probability of occurrence',
na.value = 'transparent') +
coord_equal() +
theme_linedraw()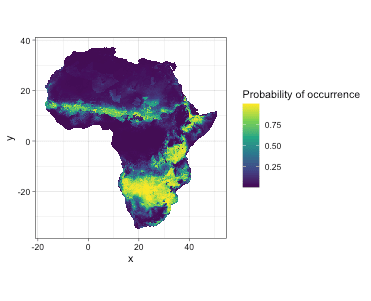
Analyze variable dependence
Randomly check variable dependence with each other.
plot(it_sdm$shap_dependences,
target_var = c('bio1', 'bio12', 'landcover'),
related_var = 'bio3', smooth_line = FALSE)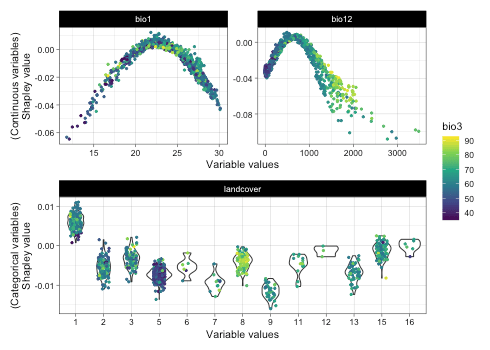
Bio3 has a strong correlation with bio12. We could check variable dependence one by one to exclude some in the final model.
Analyze variable contribution
Sometimes, we are interested in some observations, for instance, the outliers detected in the beginning steps. According to the figure below, we can tell that these suspicious outliers are not all environmental outliers.
## Analyze variable contribution for interested observations.
## For example, the first 10 outliers detected.
var_analysis <- it_sdm$vars_train %>%
slice(occ_outliers$outliers %>%
arrange(-outlier_score) %>%
slice(1:10) %>%
pull(suspious_row))
var_contrib_outliers <- variable_contrib(
it_sdm$model,
it_sdm$vars_train,
var_analysis)
# Plot contribution separately for each observation
## By default, it only plot the most 5 important variables for each observation
## You could change `num_features` to show more variables
plot(var_contrib_outliers, plot_each_obs = T)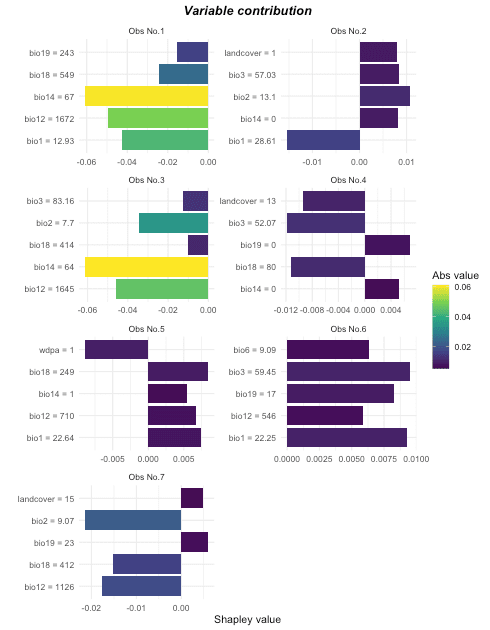
According to feature response curves and this figure, some detected outliers could be removed from training. For example, some features have a strongly negative contribution to observations No.2, No.4, and No.6 and they could be excluded.
Conclusion
With a primary analysis, we found a few obvious things to do to improve model performance:
- Add more explanatory features, such as vegetation, distance to water, elevation, slope, human influence (e.g., distance to human residential, population density, and distance to roads), etc.
- Since precipitation is more important than others to determine where elephants go. Add more bioclimatic variables related to rainfall.
- Change the way of using land cover categorical map and protected area binary map. Use ratio or distance instead.
- Delete some outliers from the occurrence dataset.
- Probably tune one or two parameters in
isotree_po. When the distribution of elephants is well studied, the model only translate the information to machine language. A good model can explain clearly and concisely but cannot tell you the knowledge that it is not taught.
The interested user could try it on their own.